


Let’s say you’ve built an amazing API using NodeJS, and you want to deploy it online to make it available for your users (or your frontend, for that matter). You deploy it to a server, but the application gets flooded with requests and crashes. Normally, you’d have to manually restart the application, perhaps by connecting to your server remotely.
Kubernetes helps us keep our API running and healthy, even when it gets taken down temporarily, perhaps by a traffic spike, or a bug in your code.
How does Kubernetes work?
Let’s review the infrastructure briefly. Here’s a simplified diagram:
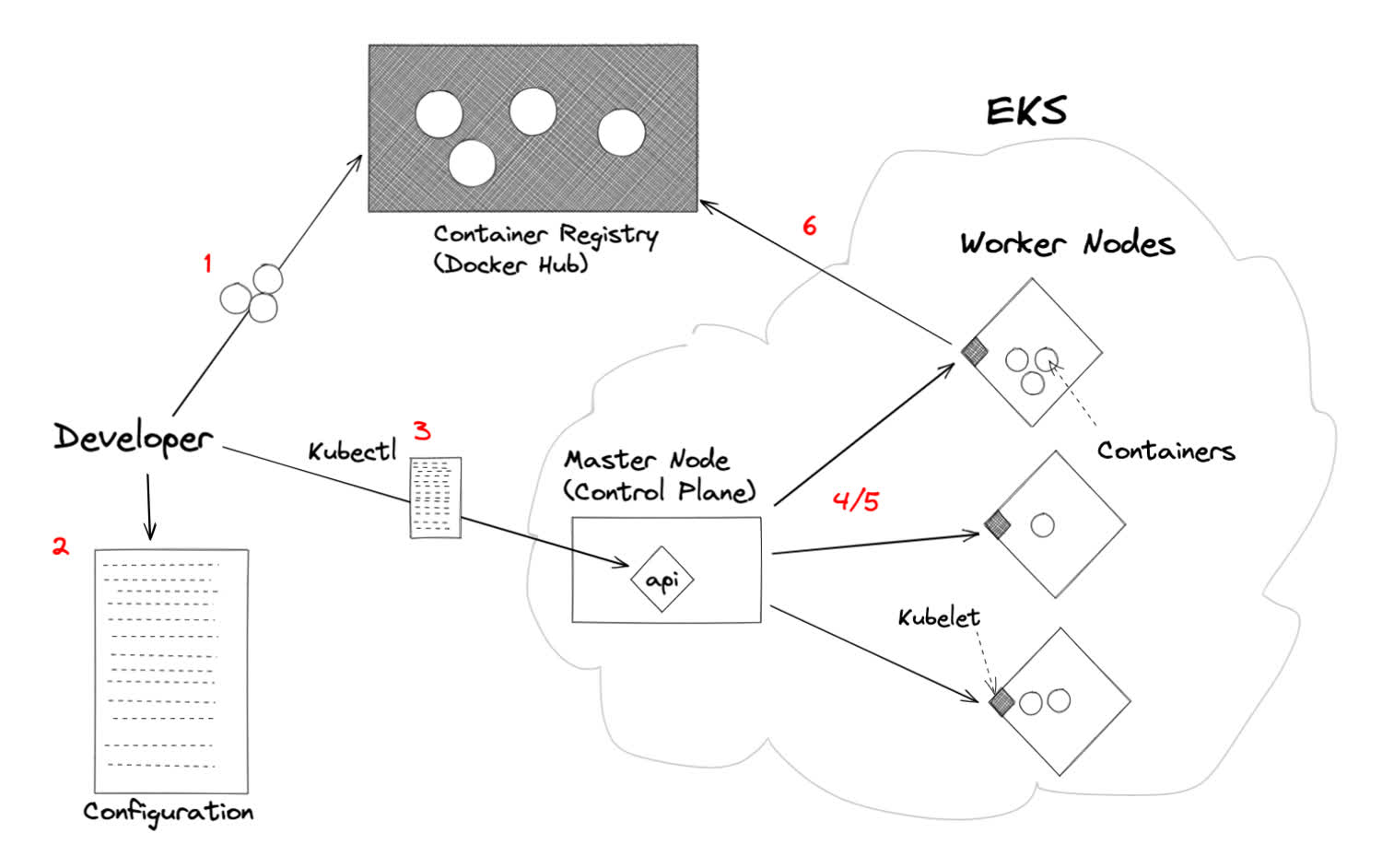
The Kubernetes ecosystem is complex! Here’s the 30,000 foot overview of how Kubernetes works.
What are all these different parts? Let’s go through it step by step.
- The developer creates a Docker image and pushes it to a container registry, likely DockerHub. These files specify how to create the Docker containers that the Kubernetes cluster is going to run.
- The developer writes up some configuration file. These are typically written as
.yamlfiles, and describe the resources that we want to create. - The developer uses the
kubectlcommand to pass that data to the Control Plane, specifically the Kubernetes API server. - The API server processes the file and, working with other parts of the Control Plane which aren’t pictured here, communicates with your worker nodes via their respective kublets.
- The API server will determine whether, based on the configuration provided, any containers need to run or be destroyed. If it need to create new ones, it’ll schedule them on the worker nodes that have space.
- The kubelets on these worker nodes will tell Docker, which is running on the nodes, to reach out to the container registry and pull down the necessary images, and start up the containers.
So, what does EKS do for us?
Simply put, EKS is Amazon’s managed Kubernetes service. It stands for Elastic Kubernetes Service.
Getting the nodes setup and running manually is complex, as is connecting our master node to our workers. This entire structure is known as a kubernetes cluster. Amazon’s EKS manages our master node(s) for us, lets us easily scale our nodes and back them up, and has all the necessary software preinstalled to run the cluster.
In order to create the EKS infrastructure, there are still a few AWS resources that we have to create. We’ll do that with eksctl, which is an open-source command line tool that wraps all of this work into a simple little helper. We’ll only have to provision our infrastructure once.
It’s important to note that EKS can be rather expensive. At the cost of $.10 per minute, it’s important not to leave your cluster running by accident. If you forget that you’re running an EKS for a month your bill may end up being quite high!
I recommend setting up billing alerts for your AWS before provisioning a cluster, so that if you accidentally leave it on, you’ll know if you’re spending more than you intended. It’s also possible to lodge a complaint with AWS’ billing team if you accidentally leave a cluster on. I’ve done this before, and they refunded my account.
Configuring AWS permissions
In order to create the resources necessary to run our cluster, we need to have a user with the necessary privileges. This can be a complex process, so for the purposes of this tutorial, I’m simply going to give the user administrative programmatic access.
Let’s create a new user inside of the Identity Access Management (IAM) console inside of AWS, and grant the user administrative privileges. At the end of this process, you should see a screen like this that gives you some keys for the user. I’m calling the user eksctl (the name of the tool we’re going to be using later in this tutorial).
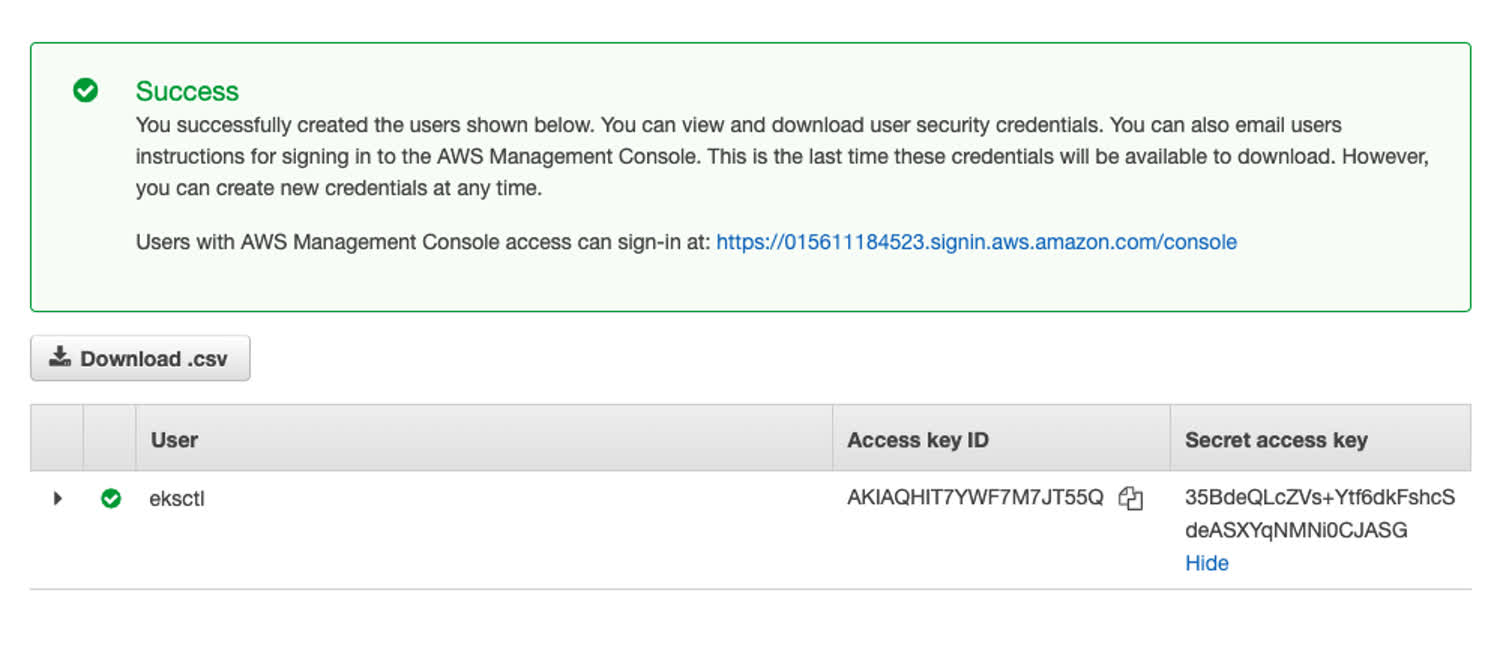
These are the credentials we’ll use to modify resources on AWS.
The screen will show you the credentials for the new user, which we’re going to save: the aws_access_key_id and the aws_secret_access_key. We’re putting both of these inside of the ~/.aws/credentials file on our computer, user a new user. This is the file that the AWS CLI picks up when running commands.
[eksctl]
aws_access_key_id=AKIAQHIT7YWF2VDNJRHL
aws_secret_access_key=cLz3BRObITWlkLtNUPSLhsJYwgpVx19BNsDigqqXNext, let’s install the AWS CLI and ensure that it’s working. I’ll leave the installation of this CLI up to you.
$ aws --version Now, we can switch to the specific AWS user we want. This will apply to the current shell. Let’s check that we’re using the right user with the aws iam get-user command:
$ export AWS_PROFILE=eksctl
$ aws iam get-user
{
"User": {
"Path": "/",
"UserName": "eksctl",
"UserId": "AIDAQHIT7YWFRRUFWV5RP",
"Arn": "arn:aws:iam::015611184523:user/eksctl",
"CreateDate": "2021-07-17T02:10:03+00:00"
}
}If we try to create our resources without providing this authentication step, we will get an error, because we will not have the necessary permissions. If you’d like to tailor the permissions more specifically, check out this article.
Creating our EKS Cluster
Now that we have a user set up, let’s create our AWS infrastructure. First, we’re going to install the eksctl command line tool. I’m on a Mac, so I’ll use brew:
$ brew tap weaveworks/tap
$ brew install weaveworks/tap/eksctlThe eksctl CLI takes a number of commands, but the one we’re interested in is the eksctl create cluster. Let’s see the various options available to us with the --help command.
$ eksctl create cluster --helpAs you can see, there are a ton of options that we can pass to the command. We could pass these all in as flags, per the AWS documentation on Amazon’s EKSCTL documentation.
Instead of passing the information as flags, we’re going to define a .yaml file that will contain our configuration. We’re going to make a configuration file like this from the eksctl repository. This allows us to commit our infrastructure files into our repository for our project. It also is repeatable and tells other developers how our project is configured.
For reference, this is the documentation for all of the fields you can pass into this configuration file.
Let’s create an infrastructure folder and place our file inside of it:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: TestCluster
region: us-east-1
nodeGroups:
- name: test-cluster-nodes
instanceType: t2.micro
desiredCapacity: 3
ssh:
publicKeyPath: ~/.ssh/id_rsa.pubLet’s break this down. The first few lines are self-explanatory; we’re using a specific version of the eksctl tool, we’re creating a cluster in a certain region, and we’re naming it. The nodeGroups field is where we can pass in a list of objects to create worker nodes for our cluster. We’re only creating one node group, of t2.micro size. Behind the scenes, each node is an EC2 server.
Our worker node group is going to have three of these nodes, and we’re enabling shell access to them with an ssh key from our local computer.
We can finally now tell eksctl to create our cluster. Let’s do a dry run first to see what it would create. Notice that we did not set many of these fields, they were applied automatically by default.
$ eksctl create cluster --config-file infrastructure/cluster.yaml --dry-runOnce we’re happy with the output, lets create the cluster.
$ eksctl create cluster --config-file infrastructure/cluster.yamlThie command will take a while. Behind the scenes, it’s going to create all the infrastructure necessary to run our cluster. To see all of the resources, head to the AWS console and go to the CloudFormation page, and select your cluster. All of the various AWS resources will be displayed under the resources tab.
We can also get a list of the nodegroups from our command line interface.
$ eksctl get nodegroup --cluster TestClusterStill don’t believe me? You can actually log into the EC2 instances that make up your cluster the same way that you would any other EC2 instance. Go to the EC2 console in AWS, and you’ll see three new EC2 instances created, with brand new IP addresses.
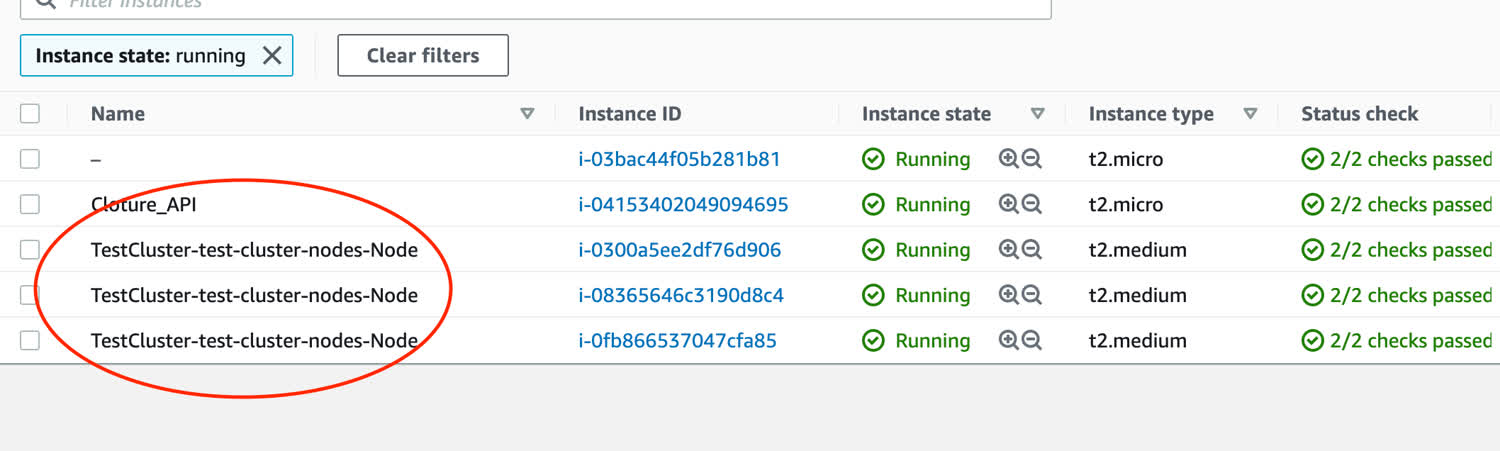
We can see that our EKS is in fact running a bunch of EC2 instances.
And because we enabled SSH access earlier, you can log into any of them with the ssh key:
$ ssh -i ~/.ssh/id_rsa ec2-user@your_node_ip_hereGreat! Our cluster is up and running, and ready to start running our containers. If at any point in the future we need to tear down our cluster, we can follow these steps. Additionally, make sure that you’re using the CLI with the correct user and permissions. The easiest way to do it from the command line is to use the eksctl delete cluster --region=us-east-1 --name=TestCluster command.
Creating our NodeJS API
Let’s create a simple API to deploy to our EKS cluster. We’re going to create a basic Express server that dishes up some random information at the /api route. Let’s initialize our npm repository and install a few dependencies:
$ npm init -y
$ npm install express fakerThe API is pretty simple, we’re using the faker package to generate some dummy data every time that request is made to our server and we’re dishing up that JSON content at the /api route:
const express = require("express");
const faker = require("faker");
const app = express();
const port = 3005;
app.use(express.json());
app.get("/api", (req, res) => {
const people = Array(20)
.fill()
.map(() => {
const first = faker.name.firstName();
const last = faker.name.lastName();
const address = faker.address.streetAddress();
const phone = faker.phone.phoneNumber();
const vehicle = faker.vehicle.vehicle();
return { first, last, address, phone, vehicle };
});
res.status(200).send(people);
});
app.post("/api", (req, res) => {
const userData = req.body;
console.log(`POST Request recieved, headers are: `, req.headers);
res.status(200).send(userData);
});
app.listen(port, () => console.log(`Listening on port ${port}!`));We’ve also setup a POST route to just send the user’s data back to them and log the headers. I’ve deliberately kept this application very simple because this tutorial is meant to focus on Kubernetes.
Dockerize our application
In the diagram at the top of this tutorial, you’ll see that the first step is the developer pushing their Dockerfile up to Docker Hub. We’re going to do that now.
The Dockerfile is also going to be pretty bare bones. We’re building off of the Node image (I chose an alpine base image so that the container will be very small). Since the alpine image doesn’t come with curl, we’ll install that ourselves. It’s going to be useful for debugging our application later on.
In our Dockerfile, we’re setting a work directory inside the container, copying over and installing our dependencies, and copying over our code. The only thing to note here is that the EXPOSE keyword does not actually expose that port, we need to do it when we run the container.
FROM node:14-alpine
RUN apk --no-cache add curl
EXPOSE 3005
WORKDIR /app
COPY package*.json .
RUN npm install
COPY index.js index.js
CMD ["node", "index.js"]Let’s build the container. If you haven’t signed up for an account on Docker Hub, make sure you do that now. Then, make sure you prefix the image with your username so that you can publish it to Docker Hub.
$ docker build -t kingofcramers/random-data .Let’s test it out now locally. The -dit flags tell the container to run in detatched mode and accept text input (in case we want to ssh into it) and the -p flag maps the port to our local machine. If you curl the endpoint, you should get the dummy data in return.
$ docker run -dit -p 3005:3005 kingofcramers/random-data
9dd0475c3fe9bba5119594cbf676ee582fbce4163dc93ad05846cf4c385b0e0b
$ curl localhost:3005/api
[{"first":"Margot","last":"Prosacco","address":"886 Nader Way","phone":"209-417-3736"...With our POST request, we should also see the user’s headers logged within the container. Let’s try making a POST request to the /api route.
$ curl -d '{ "hello": "there" }' -H 'Content-Type: application/json' http://localhost:3005/api
{"hello":"there"}
$ docker logs 9dd04
Listening on port 3005!
POST Request recieved, headers are: {
host: 'localhost:3005',
'user-agent': 'curl/7.64.1',
accept: '*/*',
'content-type': 'application/json',
'content-length': '20'
}Finally, we want to push our Docker image up to Docker hub:
$ docker push kingofcramers/random-dataWe’re done with the Docker part of this tutorial. We’ve now created our image and pushed it up to Docker Hub. We’ll eventually pull this image down and run it inside of our Kubernetes cluster. Let’s write the configuration files for our Kubernetes cluster next.
The kubectl command
We’re always going to interact with kubernetes using the kubectl command, which will communicate with the API server inside of the master node. Since we’ve already started up our kubernetes cluster, we should have an API server listening for commands.
We provide configuration for our cluster through yaml files. We send the data in these files to the API server on our master node, which then communicates with our worker nodes. For a review of why we’re choosing to create yaml files rather than passing in the information as command-line arguments, check out this post on the concept of infrastructure as code, or IAC.
Some of the commands that we’ll run from here on out will be one-liners, but they will generally only be commands that “get” the current state of our application. We’re not going to create or modify resources outside of our configuration files.
I’d highly recommend setting up an alias for the kubectl command, to make it quicker to write. For the rest of this post, I’ll be using k as an alias. I’d also recommend enabling autocompletion for your shell. I’m using ZSH, and the instructions are here, but the process is similar for Bash and Powershell
Quick note: when we do apply our configuration files, kubectl will create the resources inside of the “context” in which it’s operating. If the context is not your EKS cluster, then switch it:
$ k config use-context eksctl@TestCluster.us-east-1.eksctl.ioNow when we send commands through kubectl we will send them to the correct cluster.
Creating our first EKS Pod
This step is merely instructional. We will eventually delete this pod.
Let’s create the configuration file for our pod. Notice that it specifies the API version that we’re using, and describes the kind of resource we want to create (in this case, a pod). The spec field provides details about the pod, like the containers, volumes, and other data. In this case specifically, it details a single containers field that gives a list of the containers we want and where to find their images.
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- image: kingofcramers/random-data
name: test-pod
ports:
- containerPort: 3005
protocol: TCPOne thing to note here: Like the PORT command inside our Dockerfile, the ports field here is purely informational, the port binding will occur elsewhere in our configuration.
Let’s now create this pod inside of our cluster.
$ k create -f infrastructure/pods.yamlAfter running this command, you can check to see the pod has been created. You may also see that the pod is still creating. Give it a moment, because your cluster has to pull down this image from Docker Hub.
$ k get pods
NAME READY STATUS RESTARTS AGE
test-pod 1/1 Running 0 60sCongratulations, you’ve deployed your first container to your Kubernetes cluster! We can also see the logs of our pod (more precisely, our container). In our case, it’s the console from our Javascript file. Container logs are rotated daily and whenever the log file reaches 10MB; this command will show the latest version.
$ k logs test-pod
Listening on port 3005!Introducing Replica Sets
This is great, but it’s not actually how you’ll deploy pods to your cluster. One of the biggest benefits of Kubernetes is that it’s self-healing: when a pod goes down, either becuase of traffic spikes or other problems within the application, Kubernetes has the capacity to create a new version of that pod. However, we don’t currently have that functionality.
Let’s delete the pod. We can either specify it by name, or we can apply delete and pass in the filename, which will delete all resources in a file.
$ k destroy pod test-pod # Or k delete -f infrastructure/pods.yaml
$ k get pods
No resources in default namespaceThe pod was not recreated after it was deleted.
In order to have our containers be recreated in case of failure, we need to use Replica Sets. These are another Kubernetes resource that manage pods on our behalf. We declare how many pods we want, and the Replica Set ensures that the “state” of our application always matches. Let’s take a look at a new configuration file.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: test-rc
spec:
replicas: 3
selector:
matchLabels:
app: test-pod
template:
metadata:
labels:
app: test-pod
spec:
containers:
- name: test-pod
image: kingofcramers/random-data
ports:
- containerPort: 3005Replica Sets work by defining a “selector” on both the Replica Set and within the pod. Any pods that match the selector will be managed by the Replica Set.
When you apply this configuration file, Kubernetes will create three new pods that match the specification provided. It will restart any pods that die!
$ k create -f infrastructure/rs.yaml
replicationcontroller/test-rs createdNow let’s try deleting one of our pods (this command may take a moment). Notice that the Replica Set has already spun up a new pod in order to match the three specified in our configuration.
$ k get pods
NAME READY STATUS RESTARTS AGE
test-rs-6phnq 1/1 Running 0 3m53s
test-rs-b5ptc 1/1 Running 0 3m53s
test-rs-nh4pk 1/1 Running 0 3m53s
$ k delete pod test-rs-6phnq
pod "test-rs-6phnq" deleted
$ k get pods
NAME READY STATUS RESTARTS AGE
test-rs-6phnq 1/1 Terminating 0 5m46s
test-rs-b5ptc 1/1 Running 0 5m46s
test-rs-nh4pk 1/1 Running 0 5m46s
test-rs-qsm9p 1/1 ContainerCreating 0 2m14sDeleting a Replica Set will delete all the pods that it manages.
Debugging our application with port forwarding
When debugging an application, sometimes the easiest way to connect to the container is to use the kubectl port-forward command. This command will forward your local machine’s specified port to the port on the target pod.
Here’s a simplified example of what that looks like.
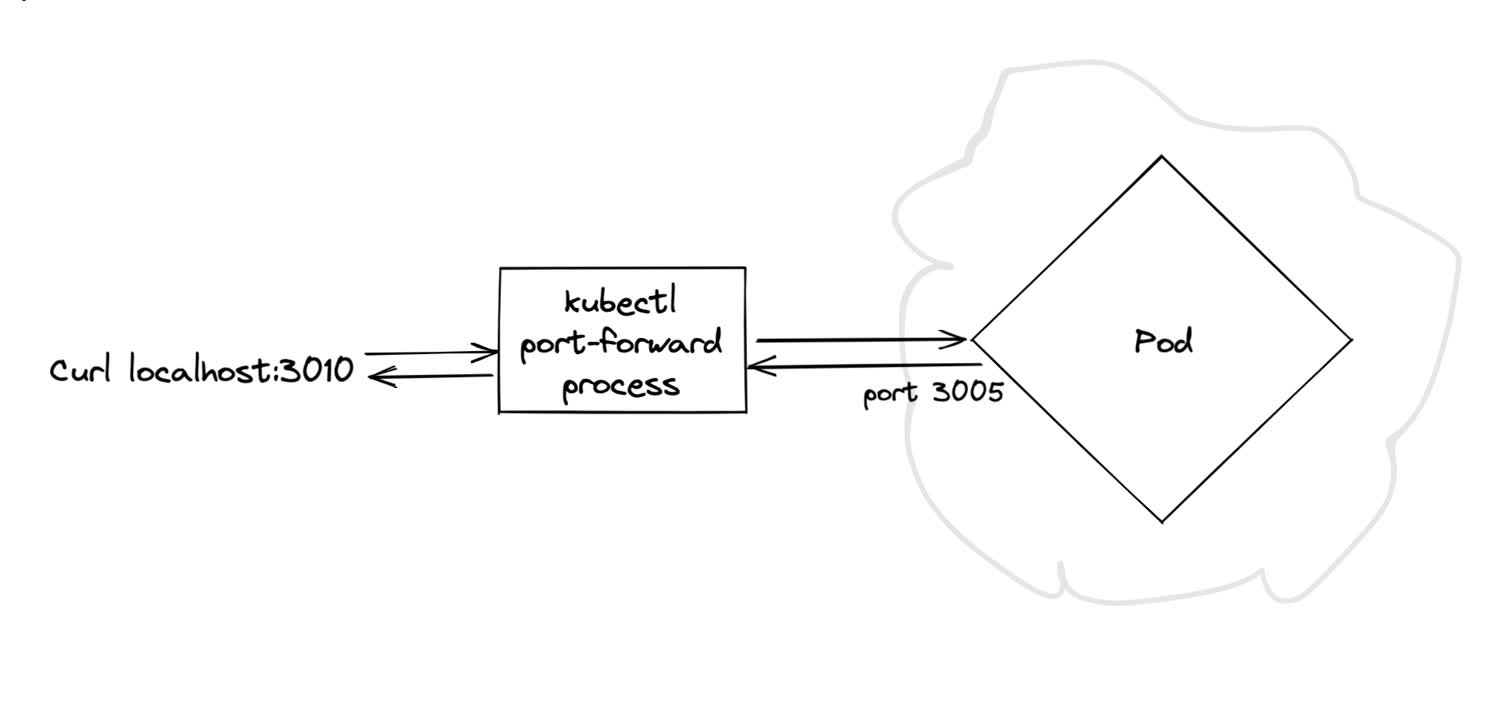
The port-forward process is responsible for mapping your requests to the correct port on the pod within the cluster.
In this example, we’ll forward the pod’s port (3005) to our local machine’s port (3010). We can now curl that address on our local machine and we’ll hit the container running inside the pod.
$ k port-forward test-rs-6phnq 3010:3005
Forwarding from 127.0.0.1:3005 -> 3005
Forwarding from [::1]:3005 -> 3005
$ curl -d '{ "hello": "there" }' -H 'Content-Type: application/json' http://localhost:3005/api
{"hello":"there"}Great, we can see that the containers are running inside of our pods, and serving our content as expected.
Exposing our pods internally with a NodePort service
This step is merely instructional. We will eventually delete the NodePort service and replace it with a LoadBalancer service.
The port-forward command is great for debugging, but it’s not really meant for production code. Instead, we’re going to create a service.
Services are Kubernetes resources that give us a single, persistent point of entry into to a group of pods. The IP addresses of pods could change when they become unavailable and are replaced, whereas the IP address of a service will never change. This gives us a consistent IP for our API.
Let’s create a NodePort service, which will let us to curl our API from within the cluster.
apiVersion: v1
kind: Service
metadata:
name: test-node-port
spec:
type: NodePort
ports:
- port: 80
targetPort: 3005 # The port on each pod
selector:
app: test-podCreate the resource.
$ k create -f infrastructure/np.yamlLet’s confirm that the service was created.
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 28h
test-node-port NodePort 10.100.37.176 <none> 80:30139/TCP 3m32sThe CLUSTER-IP field indicates that our service is now waiting for connections at the IP address of 10.100.37.176 on port 80. Keep in mind, this is an internal IP address and is not available outside the cluster.
We can connect to specific pods within the cluster using kubectl with the exec command, and the pod name: kubectl exec -it pod-name-here — /bin/sh
Let’s try it out by using the exec command to run curl inside of one of our pods, and curl that IP address.
$ k get pods
NAME READY STATUS RESTARTS AGE
test-rs-6phnq 1/1 Running 0 3m53s
test-rs-b5ptc 1/1 Running 0 3m53s
test-rs-nh4pk 1/1 Running 0 3m53s
$ k exec test-rs-6phnq -- curl -s http://10.100.37.176/api
[{"first":"Peter","last":"Turnage","address":"886 Block Drive","phone":"203-419-1013"...This works, but we want to make our cluster available to the entire internet at a specific IP address, so that anyone can query our API.
Exposing our pods to the internet
In order to make our pods available to anyone on the internet, we actually want to use a LoadBalancer service, rather than a NodePort service.
This service will create a different resource depending on where you’re deploying your infrastructure. Since we’re deploying with EKS, it’ll create AWS resources to route traffice to our cluster. Pretty cool!
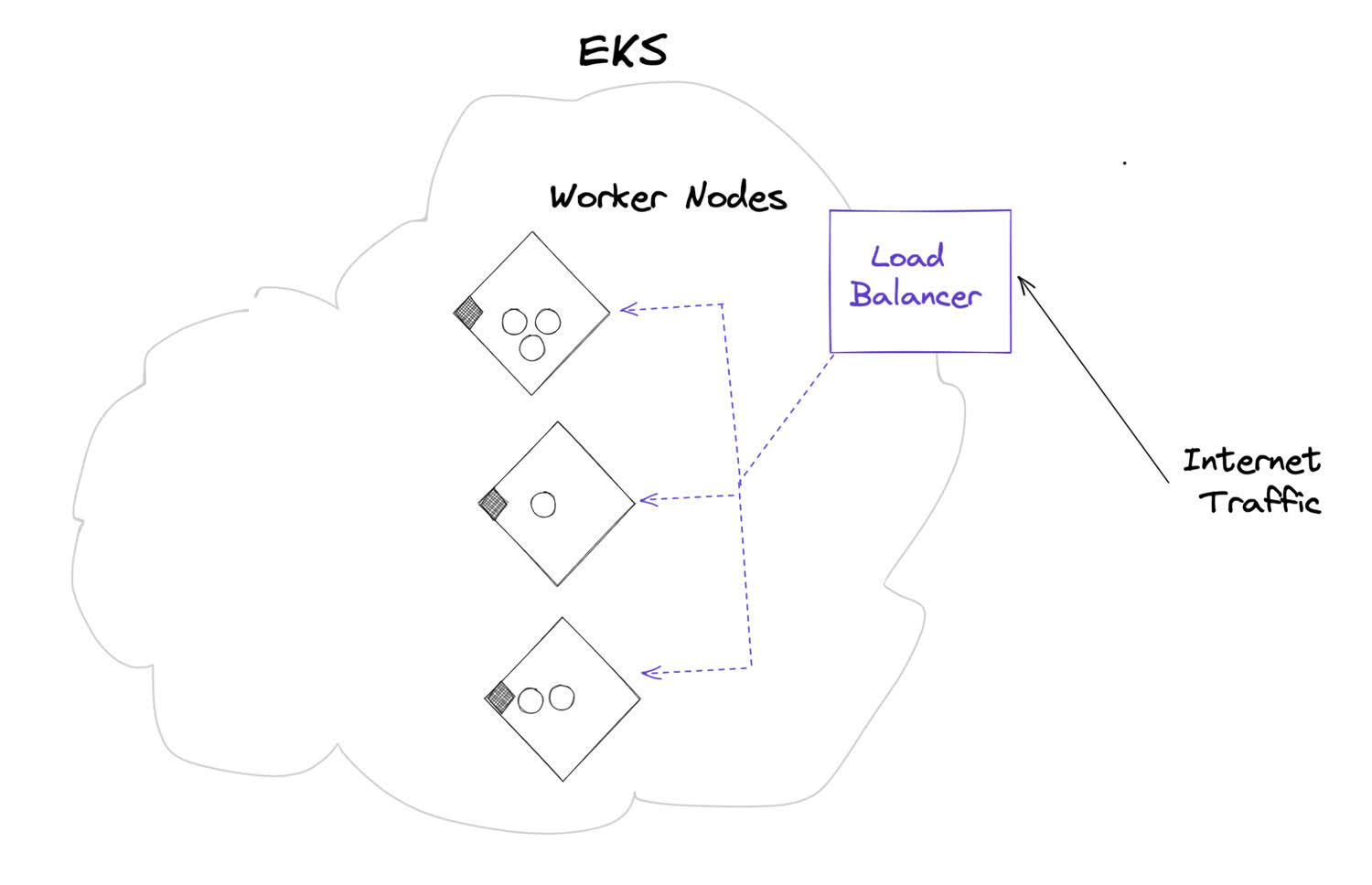
The load balancer will provide one public-facing internet address and balance traffic across all of our nodes.
Let’s first delete our old NodePort service; we don’t need that anymore.
$ k delete -f infrastructure/np.yamlCreate the configuration file for our load balancer. It’ll look very similar to our NodePort service.
apiVersion: v1
kind: Service
metadata:
name: test-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 3005
selector:
app: test-podLet’s create it, and get our services. You’ll now see a valid public IP address.
$ k create infrastructure/load-balancer.yaml
service/test-load-balancer created
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 29h
test-load-balancer LoadBalancer 10.100.40.213 a1da4187b5e3e4552b8490fe77dc59f0-1220017641.us-east-1.elb.amazonaws.com 80:32064/TCP 15mWe can now curl the IP address listed at our endpoint, and we’ll hit our server! Let’s try doing it a few times.
$ curl -d '{ "hey": "hi" }' -H 'Content-Type: application/json' a1da4187b5e3e4552b8490fe77dc59f0-1220017641.us-east-1.elb.amazonaws.com/api
{ "hey": "hi" }
$ curl -d '{ "some new data": "wow!" }' -H 'Content-Type: application/json' a1da4187b5e3e4552b8490fe77dc59f0-1220017641.us-east-1.elb.amazonaws.com/api
{ "some new data": "wow!" }
$ curl -d '{ "key one": "678" }' -H 'Content-Type: application/json' a1da4187b5e3e4552b8490fe77dc59f0-1220017641.us-east-1.elb.amazonaws.com/api
{ "key one": "678" }We can verify that our load balancer service is routing traffic to our various different pods by getting their log data. You’ll notice that the requests were load balanced across all of our pods, and that one did not recieve all of the requests.
$ k get pods
NAME READY STATUS RESTARTS AGE
test-rs-6phnq 1/1 Running 0 3m53s
test-rs-b5ptc 1/1 Running 0 3m53s
test-rs-nh4pk 1/1 Running 0 3m53s
$ k logs test-rs-nh4pk
Listening on port 3005!
POST Request recieved, headers are: {
host: 'a1da4187b5e3e4552b8490fe77dc59f0-1220017641.us-east-1.elb.amazonaws.com',
'user-agent': 'curl/7.64.1',
accept: '*/*',
'content-type': 'application/json',
'content-length': '17'
}
POST Request recieved, headers are: {
host: 'a1da4187b5e3e4552b8490fe77dc59f0-1220017641.us-east-1.elb.amazonaws.com',
'user-agent': 'curl/7.64.1',
accept: '*/*',
'content-type': 'application/json',
'content-length': '17'
}
$ k logs test-rs-6phnq
$ k logs test-rs-b5ptc
POST Request recieved, headers are: {
host: 'a1da4187b5e3e4552b8490fe77dc59f0-1220017641.us-east-1.elb.amazonaws.com',
'user-agent': 'curl/7.64.1',
accept: '*/*',
'content-type': 'application/json',
'content-length': '17'
}That’s it! Congratulations! 🎉
Next Steps
You’ve now got a load balanced API that’s serving up your data at a public IP address. You can easily scale up or scale down your API, destroy it completely. Look into liveness probes and autoscaling in order to make your API even more reslient.
For more complicated routing from the internet, you could set up an Ingress service. Since they operate on the application layer of the network stack (HTTP) they are capable of doing some things that the load balancer cannot, like cookie-based sesion affinity and intelligent routing.